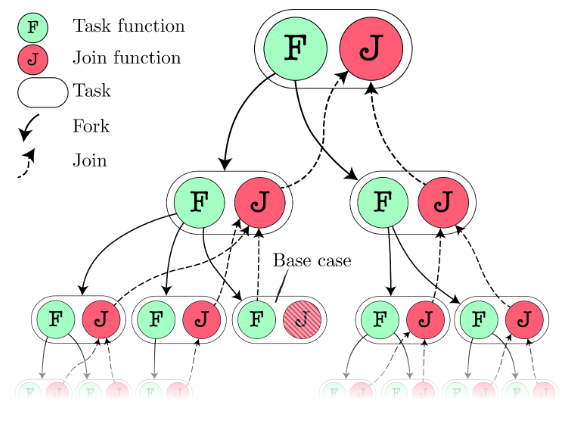
Es un estilo de paralelización donde la tarea (task) es partida en subtareas menores (subtasks). Los resultados de estos se unen (join) para construir la solución al cómputo inicial.
La división de tareas en subtareas se realiza de forma recursiva. Las subtareas son independientes, por lo que se pueden ejecutar en paralelo.
Las subtareas se pueden crear en cualquier momento de la ejecución de la tarea. Estas se crean con toda la información necesaria para ejecutarse.
Las tareas no pueden bloquearse, excepto para esperar el final de las subtareas.
Ventajas
Al no haber comunicación entre los distintos hilos, no existirán las condiciones de carrera. Por esta misma razón, estos programas son determinísticos.
Debido a la misma razón, son más eficientes. No se debe gastar recursos en crear locks para sincronizar información entre los hilos.
En el caso ideal, el tiempo de ejecución decrece de forma inversamente proporcional respecto al número de hilos, aunque puede variar por distintas causas:
- Las diferencias en el tamaño de las tareas.
- El procesamiento de la combinación de los distintos sub resultados.
- El procesamiento de la generación de hilos.
- La cantidad de hilos de ejecución disponibles.
Work Stealing
Es un algoritmo utilizado para realizar scheduling de tareas entre los hilos de ejecución. El algoritmo propone que el tiempo práctico sea lo más parecido al tiempo real. Los hilos inactivos pueden robarle tareas a los hilos ocupados.
Cada hilo tiene una cola de dos extremos (deque) donde almacena las tareas listas por ejecutar.
Cuando un hilo termina la ejecución de una tarea, coloca las subtareas creadas al final de la cola. Luego, toma la siguiente tarea a ser ejecutada del final de la cola.
Si la cola está vacía y el hilo no tiene más trabajo, trata de robar tareas del inicio de una cola de otro hilo (aleatoriamente).
La tarea se roba del inicio para minimizar las interacciones entre los hilos, pues es más probable que las tareas grandes se encuentren al inicio. Esto se debe a que en un algoritmo de “divide y conquista”, las tareas grandes generan subtareas más pequeñas y, por lo tanto, se encuentran primero.
Rayon
Es una biblioteca de Rust muy popular, que se utiliza para implementar este modelo de concurrencia.
Para realizar dos tareas en paralelo, utilizamos join
let (v1, v2) = rayon::join(fn1, fn2)Para realizar tareas en paralelo, podemos utilizar un ParallelIterator
a_vector.par_iter().for_each(|value| {
do_thing_with_value(value)
})Este método crea tantos hilos como tenga nuestro procesador para maximizar la eficiencia. Además, implementa el robo de trabajo.
Crossbeam
Es otra biblioteca muy utilizada, que provee estructuras de datos y funciones para concurrencia y paralelismo.
Ofrece crossbeam::scope para crear un nuevo entorno de hilo que garantiza que los hilos terminan antes de retornar la clausura que se le pasa como argumento a esta función. Esto nos permite crear hilos sin entregar ownership de las variables que necesita.
Posteriormente, se agregó soporte para esto en la biblioteca estándar, con std::thread::scope, por lo que ya no es necesario utilizar Crossbeam para esto, aunque sí para otras estructuras que provee.
Map Reduce
Es un modelo de programación (con una implementación asociada) para el procesamiento y generación de grandes conjuntos de datos. El modelo consiste en:
- Una función map que procesa pares clave-valor generando un conjunto intermedio de pares clave-valor.
- Una función reduce que une todos los valores intermedios con una misma clave intermedia.
Un ejemplo canónico para este modelo de programación es el de un word count.
- La función map toma frecuencias locales de una porción del texto.
- La función reduce combina las frecuencias locales en una única tabla con todas las frecuencias.
Dremel
Es un sistema de consultas en tiempo casi real, expuesto al público como BigQuery. Utiliza un lenguaje de consultas similar a SQL. Puede trabajar con una gran cantidad de registros de forma simultánea, sin siquiera tener indexación de los datos.
El sistema parte de archivos de tamaño definido donde se encuentran los datos. Estos archivos se distribuyen en servidores hoja. Estos archivos son inmutables.
El servidor en que archivo se encuentra una clave, a partir de los headers de cada archivo.
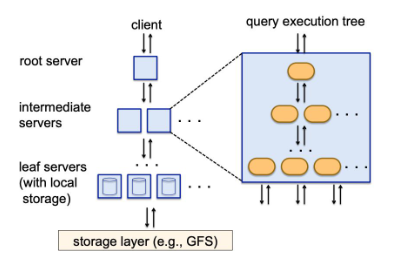
El cliente realiza una consulta al servidor raíz, el cual parte la consulta en subconsultas y las distribuye a los servidores intermedios. Estos, a su vez, parten las consultas en subconsultas y las distribuye a los servidores hoja.
Este sistema utiliza el modelo de Fork-Join para resolver consultas a gran escala de forma distribuida.