En este capítulo se introduce una implementación muy simple para un sistema de archivos, conocida como VSFS o Very Simple File System. El sistema de archivos se construye puramente sobre software, sin necesidad de características del hardware.
Hay dos aspectos principales a cubrir cuando hablamos de sistemas de archivos. El primero son las estructuras de datos utilizadas. El segundo aspecto importante son los métodos de acceso a este sistema.
Estructuras de Datos
Primero debemos dividir nuestro disco en bloques, los sistemas de archivos simples utilizan un único tamaño de bloque.
La mayor parte del sistema de archivos se utilizará para guardar información del usuario, denominaremos a esta user data.
El sistema de archivos tiene que guardar información acerca de la metadata de cada archivo. Para almacenar esta información, se suele utilizar una estructura conocida como un inodo. También se reservarán bloques para guardar información acerca de que bloques están libres y cuáles no. Para esto utilizaremos bitmaps, tanto de inodos como de bloques de usuario.
Por último, necesitaremos reservar un último bloque para guardar información sobre el file system particular.
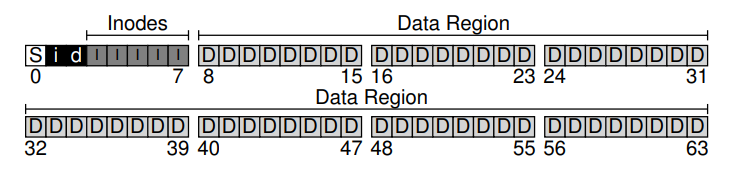
El Inodo
Una de las estructuras más importante es la del inodo. Los inodos tienen un nombre o ID que indican dónde encontrarlo. Dentro de cada inodo está toda la información que necesitamos sobre un archivo. Su tipo, su tamaño, la cantidad de bloques que necesita, la información de permisos, entre otros. Nos referimos a toda esta información como la metadata de un archivo.
Una decisión importante respecto al diseño del inodo es como nos referimos a sus bloques de datos. Un enfoque simple es el de almacenar la dirección en el disco del bloque. También se le pueden agregar niveles de indirección para permitir aumentar el tamaño del archivo.
Muchos file system almacenan algunos punteros directos a sus bloques, con algunos punteros indirectos para permitir tamaños mayores.
Directorios
Un directorio es un archivo, como cualquier otro, que contiene información acerca de los inodos a los que refiere, y sus nombres de usuario. Un mismo inodo puede ser referido por distintos directorios. Además, todos los directorios guardan dos directorios especiales. El primero es el directorio . que refiere a sí mismo, el segundo es el directorio .. que refiere a su directorio padre.
Lectura y Escritura
Cuando accedemos un archivo, el sistema de archivos primero debe encontrar el inodo deseado. Para eso, debe recorrer el path, accediendo a los directorios intermedios hasta encontrar el inodo buscado.
El primer directorio a leer debe ser el directorio root, el sistema de archivo suele conocer su ubicación de antemano. Luego, debe leer sus contenidos hasta encontrar el siguiente inodo en el cual buscar (a partir del path), este proceso se repite de forma recursiva hasta encontrar el inodo buscado.
Una vez tenemos el inodo, debemos acceder a sus data blocks para leer o escribir la información necesaria.
Cuando escribimos en un archivo, a veces es necesario reservar más bloques para el mismo, en caso de que los bloques actuales no sean suficientes para almacenar toda la información necesaria.
Optimizaciones
Las operaciones mencionadas deben realizar muchas lecturas y escrituras, por lo que muchas veces se vuelve lento. Algunos file systems utilizan memoria caché (DRAM) para almacenar bloques importantes.
Existen dos alternativas. static partitioning consiste en tener una cantidad de memoria fija para almacenar bloques populares, esto puede ser innecesario, ya que no siempre lo necesitaremos. Una alternativa. La otra opción es utilizar dynamic partitioning. La memoria puede ser reservada para el caché de forma dinámica, reduciendo así la memoria reservada innecesariamente.
Otra táctica utilizada para mejorar el rendimiento de un file system es a partir de los write buffers. Las escrituras muchas veces son retrasadas para ser enviadas de forma conjunta. Esto tiene una serie de distintos beneficios.
En primer lugar, algunas operaciones de I/O pueden ser reducidas a un menor número de pedidos si agrupamos los pedidos que refieren a un mismo archivo. Por otro lado, podemos ahorrarnos incluso la reserva de memoria si un archivo es eliminado recientemente luego de ser creado.
Además, los pedidos I/O parecen ser más rápidos de lo que realmente son, aumentando el tiempo de respuesta.
Si un sistema falla antes de que esta información sea guardada efectivamente en disco, entonces esta información es perdida.