Es el modelo distribuido de procesamiento utilizado por MongoDB.
Se basa en el particionamiento horizontal de las colecciones en chunks, que se distribuyen en nodos denominados shards o fragmentos. Cada uno de estos contendrá un subconjunto de los documentos en cada colección.
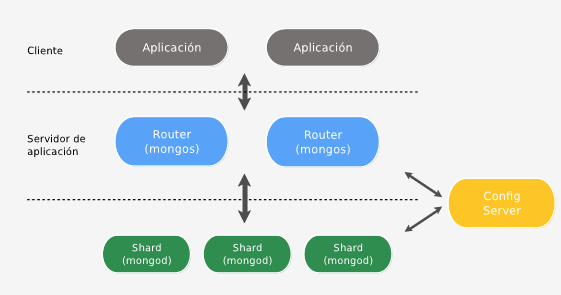
Un sharding cluster de MongoDB está formado por distintos tipos de nodos de ejecución:
- Los shards (fragmentos) son los nodos en los que se distribuyen los chunks de la colección. Cada shard corre un proceso denominado
mongod. - Los routers son los nodos servidores que reciben las consultas desde las aplicaciones clientes, y las resuelven comunicándose con los shards. Corren un proceso denominado
mongos. - Los servidores de configuración son los que almacenan la configuración de los routers y los shards.
Fragmentación
El participando de las colecciones se realiza a partir de un shard key. La shard key es un atributo o conjunto de atributos de la colección que se escoge al momento de construir el shared cluster.
La asignación de documentos a shards se hace dividiendo en rangos los valores de la clave del shard conocido como range-based sharding, o bien a partir de una función de hash aplicada sobre su valor (hashed sharding).
En un contexto de sharding es posible tener algunas colecciones sharded (fragmentadas) y otras unshared (no fragmentadas). Las colecciones no fragmentadas de una base de datos se almacenarán en un fragmento particular del cluster, que será el shard primario para esa base de datos.
La realización de sharding posee las siguientes restricciones:
- Es conveniente que la clave esté definida en todos los documentos de la colección.
- La colección deberá tener un índice que comience con la shard key.
- Desde MongoDB 5.0, una vez realizado el sharding se puede cambiar la clave. Desde la versión 4.2 se puede cambiar su valor
- No es posible defragmentar una colección que ya fue fragmentada.
El sharding permite disminuir el tiempo de respuesta en sistema con alta carga de consultas, al distribuir el trabajo de procesamiento entre varios nodos. También permite ejecutar consultas sobre conjuntos de datos que no podrían caber en un solo servidor.
El objetivo es que la base de datos sea escalable para proveer soporte al procesamiento de Big Data.
Replicación
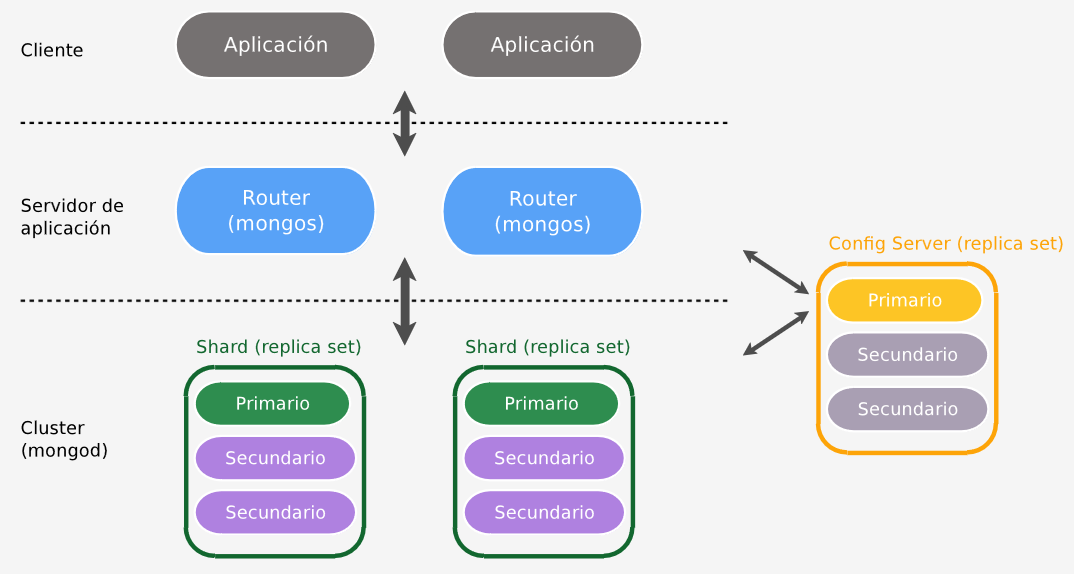
El esquema de réplicas es de master-slave with automated failover:
- Cada fragmento pasa a tener un servidor
mongodprimario y uno o más servidores secundarios. El conjunto de réplicas de un fragmento se denomina replica set. - Las réplicas eligen inicialmente un master a través de un algoritmo de elección de líder.
- Cuando el master falla, los slaves eligen entre sí a un nuevo master.
Todas las operaciones de escritura sobre el fragmento se realizan sobre el fragmento primario. Los secundarios solo sirven de respaldo.
Los clientes pueden especificar una preferencia de lecutra para que las leecturas sean enviadas a los nodos ecundarios de los fragmentos.
Nota
También los servidores de configuración se implementan como replica sets.