Surgió en Facebook en 2008, y en 2009 fue adquirida por Apache. Actualmente, es utilizada por Facebook, Twitter, Netflix.
Tiene un esquema de tablas definido, por lo que no se puede agregar datos de cualquier forma.
Utiliza una arquitectura llamada share-nothing. No existe un estado compartido centralizado, ni un controlador, ni una arquitectura maestro-esclavo. Todos los nodos son pares. Esto nos permite ofrecer mucha escalabilidad.
Está optimizado para ofrecer una alta tasa de escrituras. Utiliza una estructura de búsqueda denominada LSM Tree.
Estructura
Al esquema de una base de datos se denomina keyspace, y puede ser distribuido en varios nodos.
El concepto análogo al de tabla es el de column family, o familia de columnas. Una fila de esta “tabla” está formada por una clave simple/compuesta y un conjunto de pares clave-valor o “columnas”.
CREATE KEYSPACE empresa_db
WITH replication = {
’class’: ’SimpleStrategy’,
’replication_factor’: 1 };
USE empresa_db;
CREATE COLUMNFAMILY clientes (
cuit int,
nombre text,
domicilio text,
primary key (cuit));Wide Columns
La idea es que las columnas de una fila puedan variar dinámicamente en función de las necesidades. Es necesario indicar cuáles son las columnas que se pueden repetir.
Cuando en una fila las columnas se repiten identificadas por el valor que toman las columnas clave, se dice que la fila se convirtió en una wide row. Dentro de una misma wide row, se pueden pensar a las columnas dinámicas como sus filas.

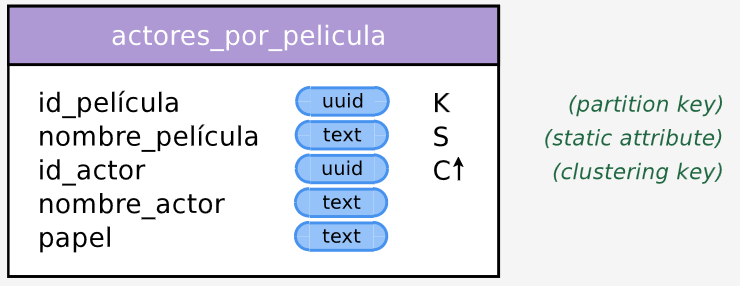
Nuestra clave primaria ahora queda dividida en dos partes. Una clave de partición, y una clave de clustering. Adicionalmente, podemos tener columnas estáticas, que sean únicas por cada partition key.
Adicionalmente, podemos tener columnas estáticas que sean únicas por cada clave de partición.
CREATE COLUMNFAMILY clientes (
nro_cliente int,
nombre text static,
ISBN bigint,
nombre_libro text,
primary key ((nro_cliente), ISBN));Al igual que en las bases relacionales, pediremos que la clave primaria permita identificar a la fila, pero además, la clave de particionado por sí sola debe alcanzar para identificar a la wide-row.
Clave Primaria
No siempre vamos a pedir que la clave sea minimal, podemos agregar a ella los atributos necesarios para las búsquedas que tengamos que hacer en esa column family.
La correcta definición de la clave primaria es fundamental para el funcionamiento de la base de datos en Cassandra. Está muy relacionada con el uso que le vamos a dar a la column-family para responder consultas.
La clave de particionado determina los nodos del cluster que se guardarán la wide-row (se utiliza hashing consistente para la búsqueda).
Toda la wide-row se almacenará contigua en disco, y la clave de clustering nos determina el ordenamiento interno de las columnas dentro de ella. Esto nos permite que las operaciones de lectura del disco sean eficientes.
Restricciones
El diseño físico de los datos en Cassandra impone algunas restricciones sobre la elección de la clave primaria de cada column family:
- Las columnas que forman parte de la partition key deben ser comparadas por igual contra valores constantes en los predicados
- Si una columna que forma parte de la clustering key es utilizada en un predicado, también deben ser utilizadas todas las restantes columnas que son parte de la clustering key, y que preceden a dicha columna en la definición de la clave primaria.
- En particular, si una columna que forma parte de la clustering key es comparada por rango en un predicado, entonces todas las columnas de la clustering key que la preceden deben ser comparadas por igual, y las posteriores no deben ser utilizadas.
Tipos de Datos
Los tipos de dato básicos son similares a los de SQL:
int,smallint,bingint,float,decimal.text,varchar.timestamp,date,timeuuid- `boolean
Cassandra permite trabajar con colecciones como tipos de datos:
set: Conjunto de elementos.list: Lista ordenada de elementos.map: Conjunto de pares clave/valor.
Reglas de Diseño
Para diseñar una base de datos en Cassandra, debemos tener en cuenta los siguientes puntos:
- No existe el concepto de junta. Si para alguna consulta típica necesitamos el resultado de una junta, entonces debemos guardarla como una tabla desnormalizada.
- No existe el concepto de integriadad referencial. Si la necesitamos, debe ser manejada desde el nivel de aplicación
- Desnormalización de datos. En las bases de datos NoSQL el uso de tablas no normalizada está a la orden del día, y básicamente por un único motivo: performance.
- Diseño orientado a las consultas: Las consultas preceden al modelo de datos, debemos pensar de antemano que consultas haremos para poder diseñar las tablas.
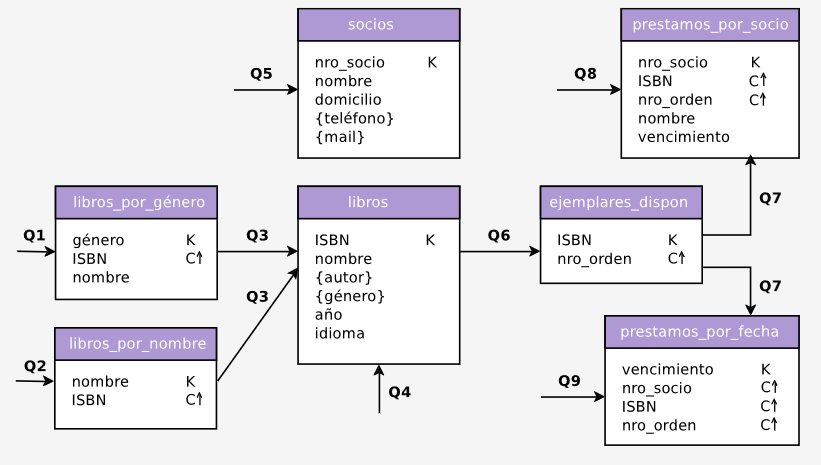
Chebotko
Se han propuesto distintos diagramas para el modelado lógico en Cassandra. Nosotros utilizaremos uno de los más conocidos: Chebotko.
Además, podemos representar flujos de consultas a partir de unir las familias de columnas.