La necesidad de diseñar un Gestor de Base de Datos no relacional surgió en la década del 2000 a partir de la masificación de la WEB. Se buscaban diseñar soluciones al problema de almacenamiento que tuvieran:
- Mayor escalabilidad para trabajar con grandes volúmenes de datos. Fue uno de los objetivos principales en el desarrollo de BigTable (Google, 2005)
- Mayor performance en las aplicaciones WEB. Se buscaban formatos que fueran fáciles de serializar, como XML y JSON.
- Mayor flexibilidad sobre las estructuras de datos. Queremos permitir una estructura que facilite la evolución de datos (agregado de columnas). En un modelo relacional, el sistema es muy rígido. El desarrollo WEB busca darle mayor libertad al desarrollador para organizar los datos.
- Mayor capacidad de distribución. Se busca tener mayor disponibilidad y tolerancia a fallas. Para ello, se requieren mecanismos de replicación y fragmentación automática de los datos. Se prioriza la capacidad de procesamiento distribuido.
Clasificación
Tendremos cuatro tipos principales de bases de datos no relacionales:
- Gestores de Clave Valor: Permiten guardar información en un formato de diccionarios, con clave y valor.
- Gestores Orientados a Documentos: Permiten guardar documentos como JSON o XML.
- Gestores Wide Column: Tienen diccionarios con columnas que permiten ser extendidas, pero con ciertas reglas. Tienen una serie de “columnas” que se repiten.
- Gestores Basados en Grafos: Ordenan la información en grafos.
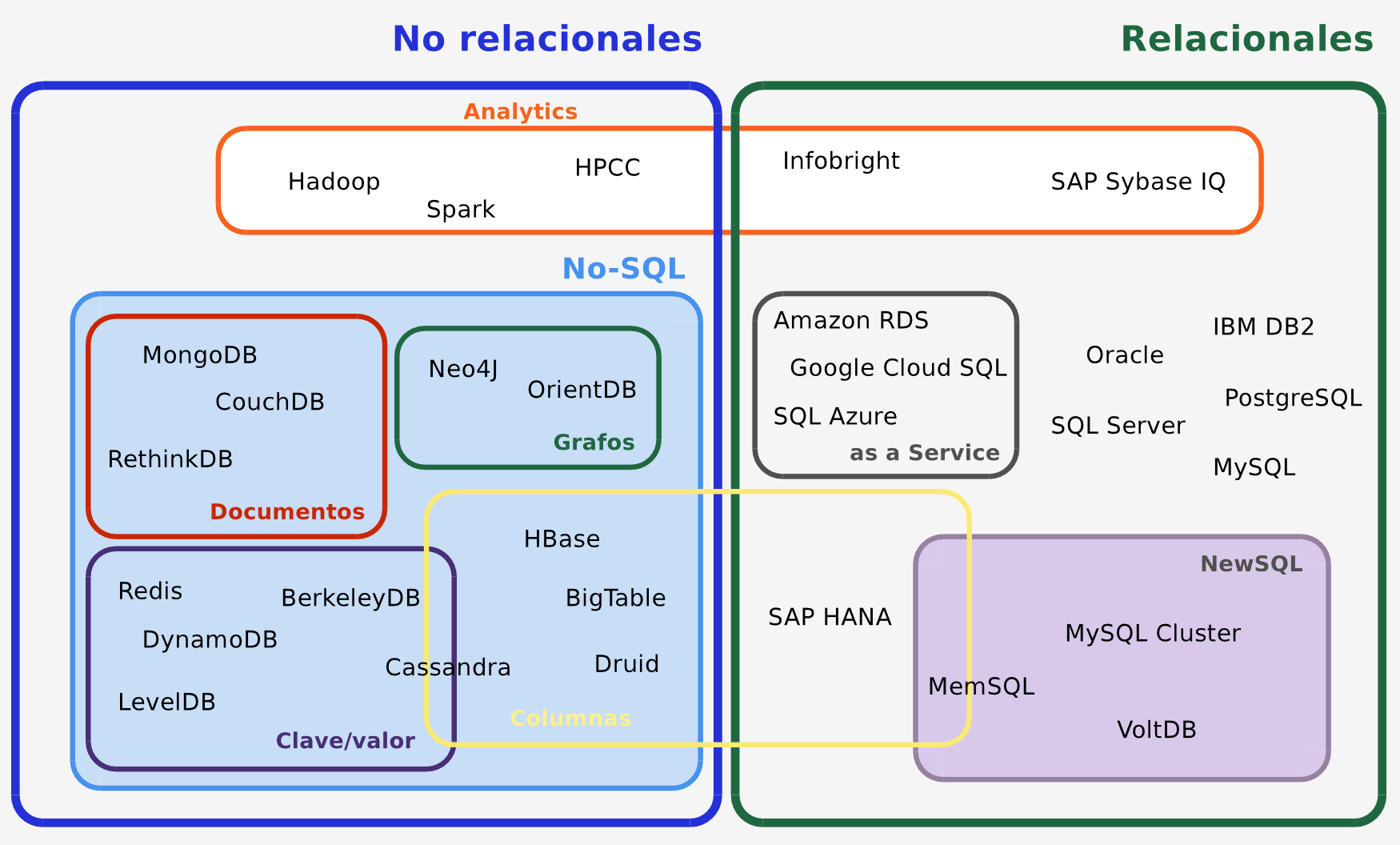
En cada uno de ellos cambia la definición de agregado, es decir, de como conjuntos de objetos relacionados se agrupan en colecciones para ser tratados como una unidad y ser almacenados en el mismo lugar. Las bases de datos relacionales y las basadas en grafos carecen de la noción de agregado.
Nota
En el caso de una base de datos orientada a documentos, los documentos serán los agregados.