El enfoque de separar el espacio de direcciones en piezas de tamaño variable (segmentación) puede tener dificultades, por lo que vale la pena considerar un segundo enfoque: dividir el espacio en piezas de tamaño fijo (paginación) usualmente con un tamaño de 4kb.
En lugar de partir el espacio de direcciones, lo dividimos en unidades de tamaño fijo a las cuales llamaremos páginas. Luego, veremos la memoria física como un arreglo de espacios fijos llamados page frames. Cada uno de estos contiene una sola página de memoria virtual.

Este enfoque tiene un cierto número de ventajas:
- Flexibilidad: el sistema puede soportar las abstracciones de espacios de memoria virtuales de forma efectiva, sin importar como utiliza el espacio de memoria ese proceso.
- Simplicidad: no tiene que buscar espacios de memoria con los tamaños deseados, ya que los tamaños son todos iguales. Solo necesita encontrar la cantidad de páginas deseadas.
- Sin fragmentación externa: como las páginas son de tamaño fijo, no necesita buscar las que tienen un tamaño particular
Sin embargo, todavía hay algunos problemas a resolver cuando trabajamos con paginación.
Traducción de Direcciones
Para conocer donde cada página virtual se encuentra en la memoria física, el sistema operativo guarda una page table por cada proceso, allí se encuentran las traducciones para cada página virtual.
Para traducir una dirección de memoria, primero se debe separar la dirección de memoria virtual en dos partes: las VPN o virtual page number, y un offset dentro de esa página.
Luego se busca, para el proceso actual, en que dirección de memoria se encuentra el número de página virtual y realiza la traducción al número de página física: PFN o physical frame number.
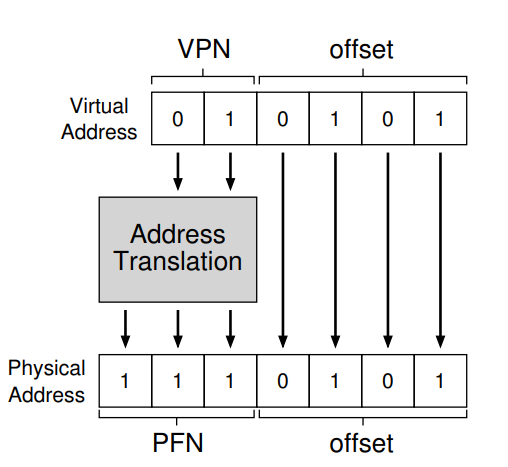
Page Tables
Estas page tables pueden volverse muy grandes, mucho más que la que teníamos con segmentación. Supongamos que necesitamos 4 bytes por cada page table entry o PTE, entonces necesitaremos 4 MB por cada page table (una para cada proceso). Esto es una inmensa cantidad de memoria. Debido a su tamaño, no las guardaremos en la MMU. Al estar guardadas en memoria, la traducción será lenta, más adelante veremos como acelerar esto utilizando caché.
Una page table es una estructura de datos que se usa para traducir direcciones de memoria virtuales. La más simple es una linear page table, este es simplemente un vector donde en cada índice es la VPN, y cada valor es PFN. Más adelante, veremos estructuras más eficientes.
Dentro de cada page entry, tendremos ciertos bits que nos dan información sobre cada traducción:
- El valid bit nos indicará si la traducción es válida. Es decir, si esa página le pertenece al proceso.
- El protection bit nos indica que permisos se tienen sobre esa página (lectura, escritura, ejecución).
- El present bit indica si la dirección se encuentre en memoria o en el disco.
- El dirty bit nos indica si la página fue modificada desde que se trajo a memoria.
- El reference bit se utiliza para si la página fue accedida, vital para el page replacement.
Velocidad de Traducción
La paginación es lenta, cuando se accede a una dirección de memoria virtual, el hardware deberá primer ver donde se encuentra la page table del proceso actual, para poder traducirlo. Podemos asumir que la dirección física de la page tables encuentra en un registro especial del procesador.
Luego, deberá acceder a la memoria para buscar la traducción de esa dirección de memoria, esto es un proceso lento. Una vez encontrada la dirección de memoria, se le debe concatenar el offset para hallar la dirección de memoria física.
Cuando se ejecuta una instrucción, se deben generar dos referencias a memoria: una de la page table del proceso, para encontrar la dirección de memoria de la página virtual. Y otra de la dirección de memoria física de la instrucción que se debe buscar.
Estas referencias a memoria son costosas, lo que ralentizará el proceso en ejecución. Vemos, entonces, las dos problemáticas principales de utilizar paginación.