Es un sistema que permite compartir archivos en redes locales e intranets.
Posee un esquema centralizado de información persistente, ofrece control de backups y control de acceso y monitoreo.
Además, permite optimizar los recursos debido a la centralización, ya que podremos tener discos de mayor capacidad y menor costo de administración.
Los factores de diseño de este sistema son:
- Transparencia a los clientes:
- Acceso: obtener los recursos con credenciales usuales.
- Localización: operar con archivos como si fueran locales.
- Movilidad: el movimiento interno de archivos no debe ser percibido.
- Performance: las optimizaciones no deben afectar al cliente
- Concurrencia: El acceso concurrente no debe requerir operaciones particulares de los clientes.
- Heterogeneidad de Hardware: El sistema puede estar compuesto por hardwares distintos.
- Tolerancia a Fallos: Capacidad de ocultar o minimizar fallos.
Network File System (NFS)
Fue diseñado para ser independiente de las plataformas, pero desarrollado en UNIX en 1984.
Desde un primer lugar, se diseñó para que el file system siga el estándar POSIX.
Requiere de una abstracción del kernel llamada Virtual File System. Las aplicaciones utilizarían VFS para acceder los archivos, lo que requiere de una invocación remota.
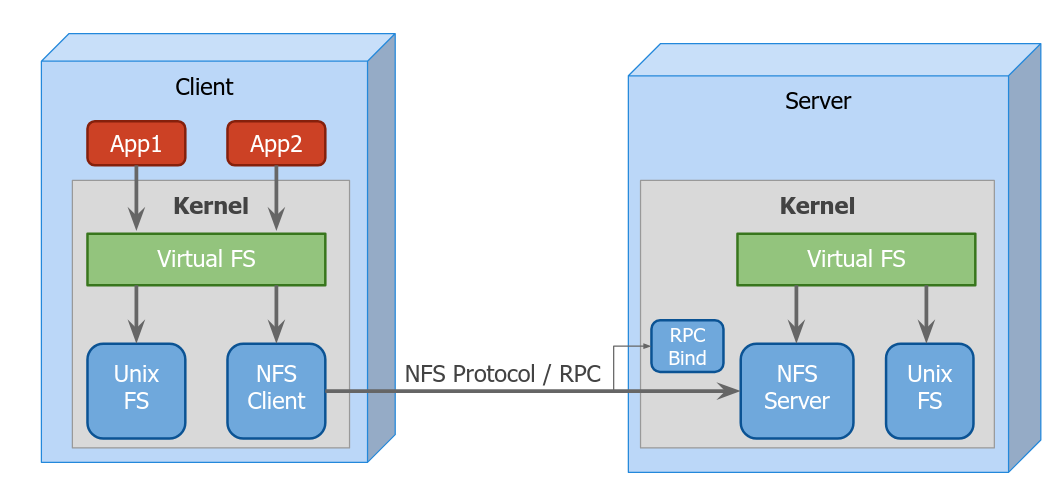
Las consultas se harían utilizando RPC, tanto sobre UDP como TCP.
No está pensado para grandes volúmenes de datos, sino para compartir información en una red interna.
Hadoop DFS (HDFS)
Es un sistema de archivos distribuido, diseñado para utilizar hardware de bajo costo. La implementación está basada en el diseño de Google File System (GFS).
No soporta el estándar POSIX, por lo que se considera un storage en lugar de un file system. Se pensó para soportar operaciones útiles en ambientes de cómputo distribuido (como Map Reduce).
Los factores de diseño del sistema, son:
- Tolerancia a Fallos: Los fallos en el hardware son comúnes, por lo que es mas económico soportarlos.
- Volumen y Latencia: Favorece operaciones de streaming, y sobre archivos volumétricos.
- Portabilidad: Preparado para ser ejecutado en hardware de bajo costo, utilizando TCP entre servidores, y RPC con los clientes.
- Performance: Favorece operaciones de lectura.
Arquitectura
La arquitectura consta de:
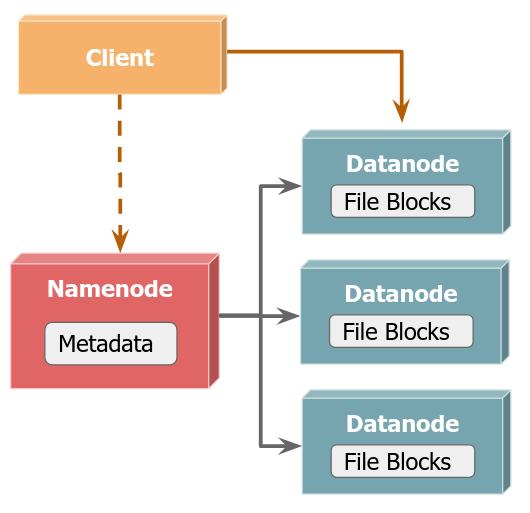
- Un namenode que conoce donde está cada porción de cada archivo y contiene toda la metadata.
- Múltiples datanodes, que contienen los contenidos de los archivos.
Los clientes consultan al namenode por el file system y la ubicación de los archivos, y luego se comunican con los datanodes correspondientes.
Almacenamiento de Datos
Los archivos se particionan en bloques de 128 MB, y los bloques son replicados en distintos datanodes.
El namenode mantiene el listado de datanodes para un archivo. La metadata se mantiene en memoria para optimizar su acceso, con un log de transacciones.
También se permite un rebalanceo de bloques entre los datanodes.
Acceso a Datos
Una operación es mucho más eficiente si se encuentra cerca de los datos con los que opera.
“Moving computation is cheaper than moving data”
Para el acceso a los datos se favorece el principio de localidad de los datos. El cliente obtiene una lista de datanodes para cada bloque y sus réplicas, y se intenta acceder a los bloques más cercanos (del mismo rack en caso de ser posible, o del mismo datacenter).