Es un patrón para manejar el storage en un sistema distribuido. Brinda la ilusión de que los procesos tienen una memoria compartida centralizada.
Es un patrón intuitivo, y permite que los algoritmos no distribuidos se traduzcan fácilmente, pero desalienta la distribución, es poco performante, y tiene un único punto de falla.
Enfoque naive
La información es almacenada en el servidor. Los clientes acceden mediante consultas de escritura y lectura sobre las paginas. El servidor puede garantizar la consistencia muy fácilmente serializando los consultas.

Este enfoque ofrece muy baja performance.
Migración de Memory Pages
La información es almacenada en el servidor, pero delegada a los clientes. Esto permite a los clientes manejarla y optimizar su acceso. Otros clientes pueden pedir la página delegada y quedar bloqueados, o pedirla al cliente que la tiene (subdelegación).

Este enfoque no permite acceso concurrente a una página, pero permite optimizar la localidad de acceso, gracias a la delegación.
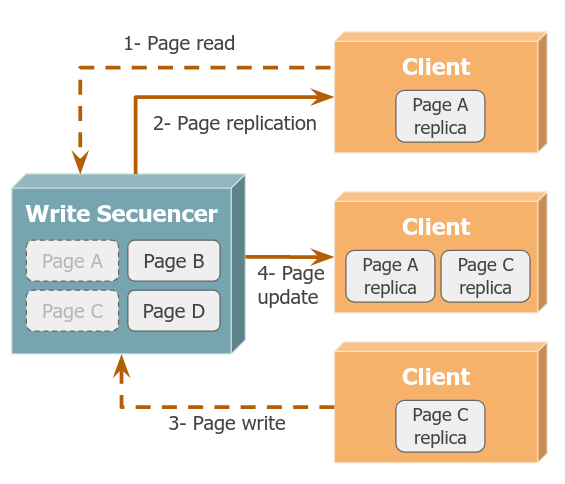
Replicación de Memory Pages
Las lecturas implican una replicación read-only, y las escrituras son coordinadas por el servidor, invalidando a las réplicas.

Este enfoque favorece un escenario de muchas lecturas, y pocas escrituras.
Si queremos permitir lectura-escritura, entonces el servidor funciona como un secuenciador de operaciones. Las páginas se encuentran en múltiples lugares a la vez, y el servidor debe notificar a las réplicas cuando se deben actualizar las réplicas.