Es un paradigma desarrollado por Google en 2005. La idea es identificar tareas que pueden ser ejecutados en paralelo, y grupos de datos que puedan ser procesados en paralelo.
Algunas implementaciones de este paradigma son: Apache Hadoop, Amazon EMR, Google MapReduce.
Está inspirado en las funciones map y reduce de los lenguajes funcionales.
Arquitectura
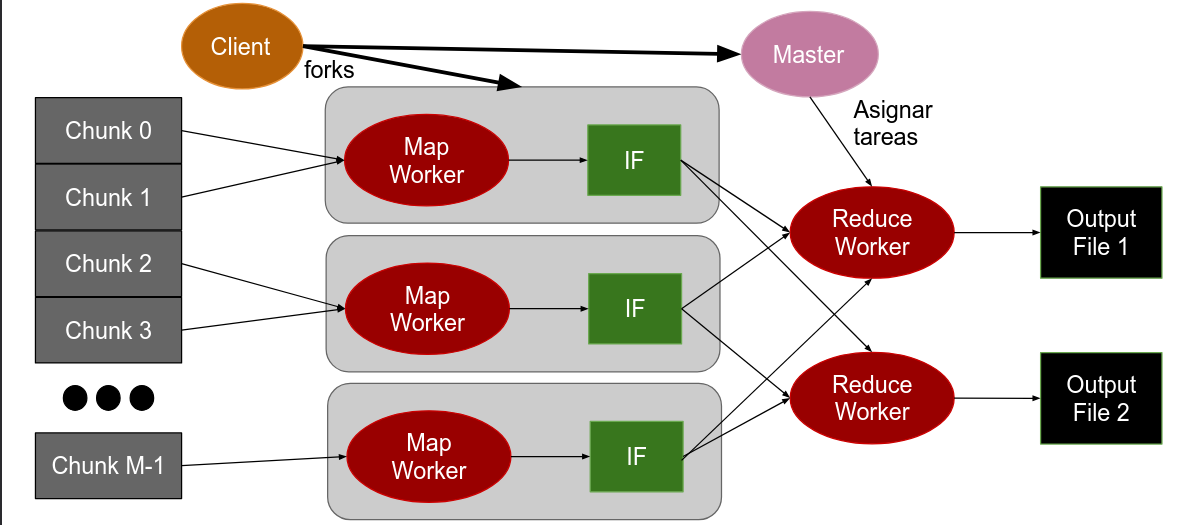
En el caso ideal, no existe la dependencia entre los datos. Estos pueden ser partidos en chunks del mismo tamaño (por lo general 64 MiB).
Cada proceso pueden trabajar con uno o múltiples chunks, de forma uniforme
El coordinador, o proceso master, es el encargado de:
- Dividir los datos en chunks.
- Enviar la ubicación de los chunks a los workers.
- Recibe la ubicación de los resultados de todos los workers.
Los workers, son los encargados de:
- Recibir la ubicación de los chunks del proceso master.
- Procesar los chunks de información.
- Envía la ubicación del resultado del procesamiento al master.
La cantidad de mappers y reducers es especificada por el usuario. En un caso idea, tendríamos un mapper por cada chunk.
Lógica de Negocio
La lógica de negocio, provista por el usuario, son las funciones map y reduce.
La función map recibe un chunk y devuelve un resultado intermedio como un conjunto de pares clave-valor.
map: (input shard) -> intermediate(key/value pairs)No se puede llamar a la función reduce hasta que se hallan procesados todos los datos, por lo que los datos intermedios se guardan en un archivo intermedio (IF). Una vez procesados todos los datos, se le notifica al master la ubicación del archivo master.
El proceso master toma los archivos intermedios y los agrupa por clave. Luego particiona los datos intermedios en regiones, una para cada reducer. Finalmente, el master le envía la ubicación de los archivos intermedios a los reducers.
Cada clave única es procesada por un único reducer, pero un reducer puede procesar más de una clave.
La función reduce recibe un conjunto de pares clave-valor. Esta función es llamada por cada clave única, y devuelve el resultado final del procesamiento.
reduce: intermediate(key/value pairs) -> result files