Es una plataforma para procesamiento distribuido de datos. Incluye un motor de ejecución de pipelines de transformación.
Ofrece distintos niveles de abstracción para desarrollar las aplicaciones:
- DataStream: Es la interfaz principal, para definir pipelines, y ofrece el mayor control.
- Table API: Es un lenguaje declarativo para especificar consultas utilizando tablas, siguiendo el modelo relacional.
- SQL: Lenguaje de alto nivel para especificar consultas, similar a Table API, pero en formato SQL.
El framework permite definir un dataflow, que es un DAG de operaciones sobre un flujo de datos.
Algunos casos de uso comunes son:
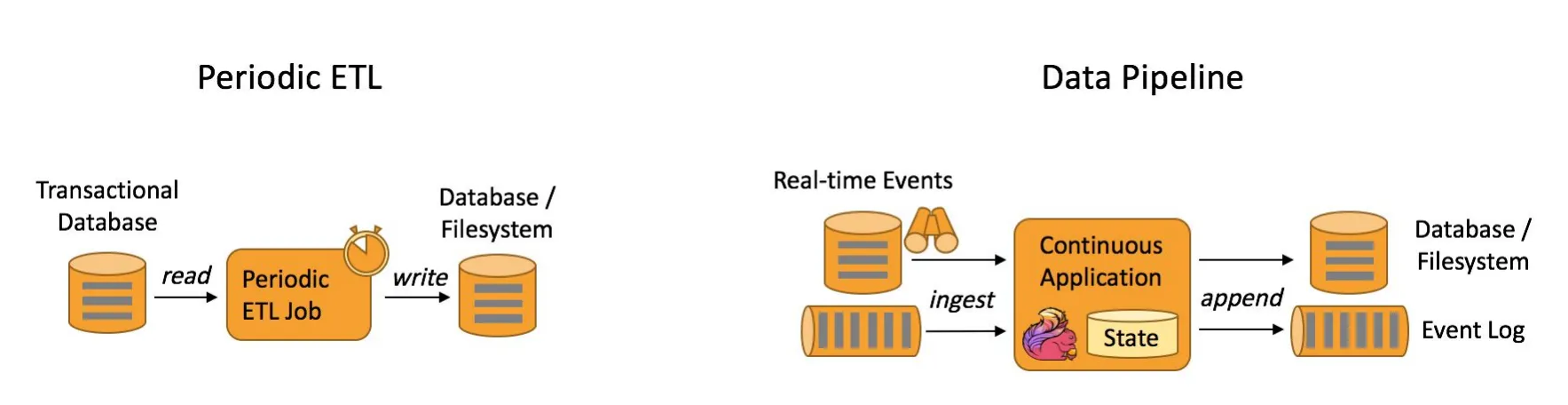
- ETL (extract, transform and load): Operaciones programadas de modificación de datos, con origen y destino en un base de datos.
- Data Pipelines: Tareas de procesamiento recurrentes, basadas en la ocurrencia de eventos.
Se pueden utilizar múltiples pipelines de Flink que procesan distintos datos y colaboran entre sí.
