Es un servicio de PaaS de Google, iniciado en 2008. Ofrece servicios gratuitos y servicios de pago.
Objetivos de Diseño
El concepto consiste en una plataforma donde las buenas prácticas son forzadas:
- Los sistemas son granulares.
- El escalamiento es horizontal.
- Las consultas son breves, con posibilidad de encolar consultas largas.
- Independencias del sistema operativo y el hardware.
Además, ofrece los siguientes servicios:
- Cache.
- Colas de mensajes.
- Elasticidad.
- Versionado.
- Herramientas de logging, debugging, monitoreo, etc.
- Modelos no-relacionales con Datastore y BigTable.
Microservicios
Se definen aplicaciones que pueden comunicarse entre sí. Cada aplicación tiene servicios, que pueden comunicarse entre sí.
A su vez, los servicios tienen su capa de caché, su capa de datastore, y un servicio de colas. Hoy en día, estos servicios evolucionaron y se ofrecen por separado.
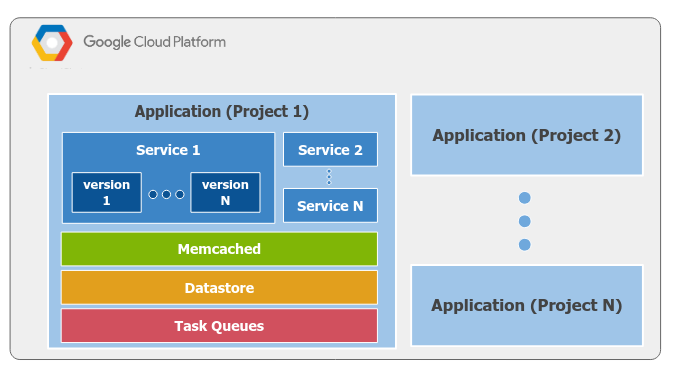
Un servicio (módulo), que permite mantener unidad entre las operaciones soportadas. Pueden desplegarse distintas versiones a la vez, y para cada versión pueden existir una o más instancias.
Una instancia (app servers o backend servers) es una unidad de procesamiento, que puede ser dinámica o residente:
- Instancias dinámicas:
- Se crean dinámicamente, aunque hacerlo toma un poco de tiempo.
- Procesan consultas pequeñas.
- Fuerzan respuestas rápidas y sin manejo de estado.
- Pueden aceptar consultas externas o internas.
- Instancias residentes:
- Son creadas de forma manual mediante configuración. A veces es preferible tener instancias precalentadas (warmed up) para evitar el costo de inicio ante una consulta.
- No existen límites para su empleo y se pueden elegir su capacidad de cómputo
- Procesas consultas largas, especialmente en baches (con o sin estado)
Arquitectura
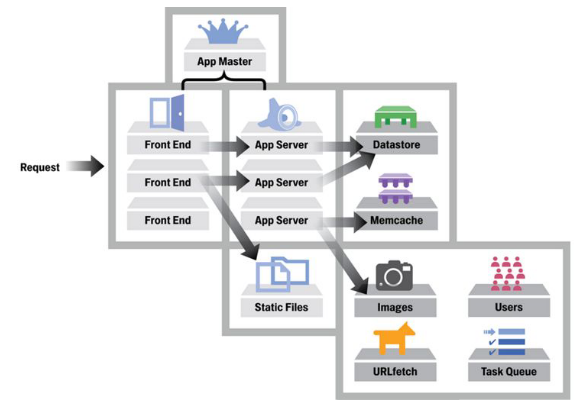
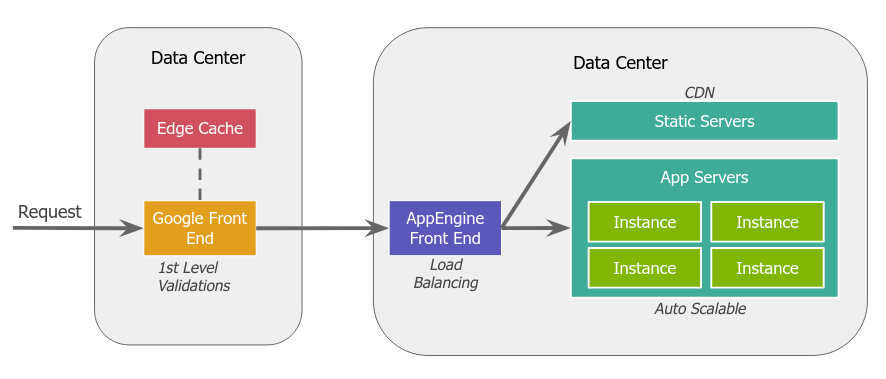
Hay front servers que reciben peticiones, responden las que ya tiene cacheadas. Las consultas que no pueden ser resueltas son reenviadas a la aplicación.
Las consultas llegan a una cola de tipo push. En lugar de esperar a que otro proceso tome el mensaje, la cola es un elemento activo que puede crear instancias de forma dinámica. Además, puede actuar como balanceo de carga.
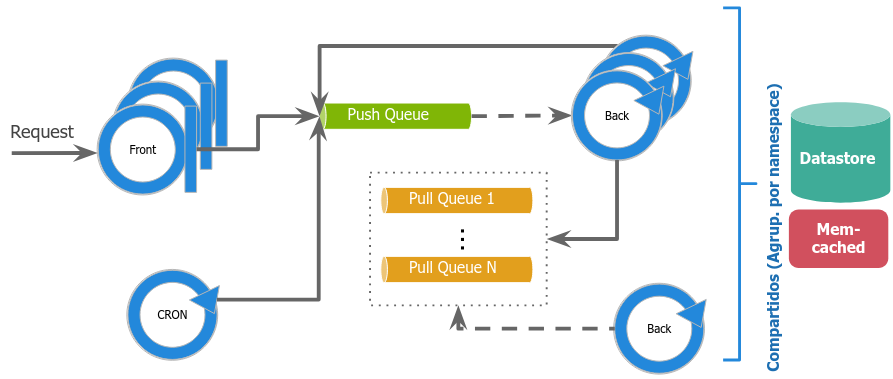
Las consultas largas van a otras colas de tipo pull para ser resueltas de forma asincrónica, por un proceso residente.
Las instancias acceden a un almacenamiento compartido.
Tipos de Colas
Hay dos tipos principales de colas:
- Colas de push:
- Envían consultas a instancias activas.
- La url define la instancia, servicio, y versión a atender el mensaje.
- El payload está dado por los argumentos en la URL y los headers.
- Colas de pull:
- Permiten encolar tareas para ser consumidas de forma controlada.
- Los mensajes están en modo leasing: los mensajes son prestados de la cola hasta que se marcan como procesados. Es un mecanismo similar al ACK de las colas de RabbitMQ.
- Es el enfoque más usual de colas de tareas.
Almacenamiento
Utiliza Datastore, una base de datos no relacional administraba por Google.
- Es un modelo de objetos con atributos, llamados entities.
- Los tipos no tienen un esquema, pero tienen atributos indexables, llamados kinds.
Este almacenamiento es altamente escalable en el volumen de datos:
- Está basado en BigTable.
- Soporta entidades de hasta 1 MB.
- Permite consultas por clave, o por atributos indexados.
- Soporta millones de escrituras por segundo, pero no está optimizado para consultas.
- Garantiza operaciones ACID, incluso entre entidades.
Particionado
Los datos se particionan de modo que los árboles de entidades se encuentren en lugares cercanos. Esto permite operaciones atómicas sin tener que sincronizar nodos.
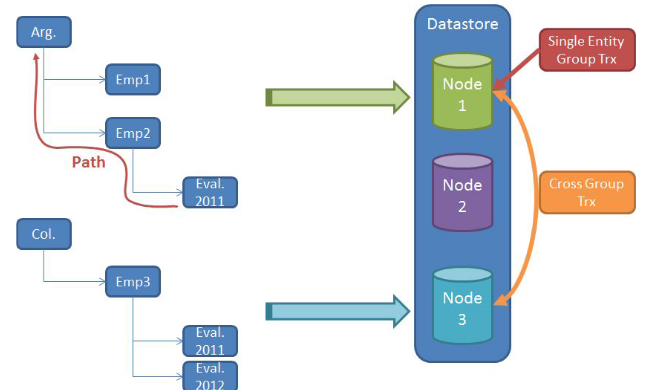
Si los datos involucran múltiples nodos, entonces se tienen que usar cross group transactions. Este es un mecanismo muy costoso.