Para poder acceder a la información de forma eficiente (y distribuida), existen distintas técnicas posibles.
LSM Tree
El LSM Tree, o log-structured merge tree es una estructura de búsqueda que mantiene parte de sus datos en memoria, para diferir los cambios sobre el índice en disco.
Fueron introducidos en 1995, y google los utilizo para BigTable en 2005. Desde entonces fueron adaptados por Apache Cassandra y MongoDB, entre otras bases de datos NoSQL.
Se busca acceder en forma secuencial a disco, para mejorar el trade-off entre el costo de hacer un disk seek y el costo de un buffer en memoria. Esto ha sido bastante estudiado y se conoce como five-minute rule.
Tendremos tres árboles formados, uno en memoria, y dos en disco:
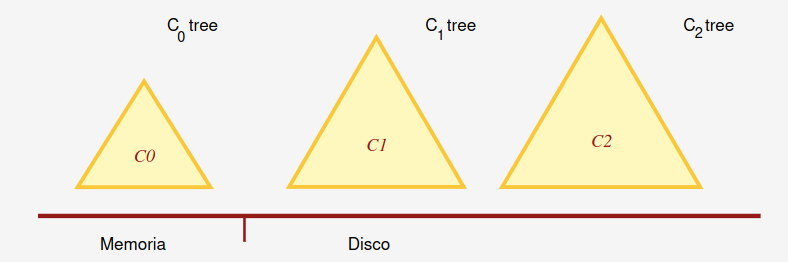
El costo de escritura y lectura en es nulo. Desde que se inserta una entrada en hasta que se traslada a habrá una demora. Una vez alcanza un tamaño considerable, se inicia un proceso de rolling merge (flush). El árbol se vuelve a escribir de forma completa, esto implica que no hay escritura aleatoria, sino ordenada.
El árbol suele tener una estructura similar a un árbol B, mientras que está en memoria, por lo que no es necesario minimizar su profundidad, suelen emplearse árboles balanceados como el árbol 2-3 o el árbol AVL.
Se suele mantener más de un nivel en disco, y varios archivos por nivel. Estos se unen cunado superan un umbral. Esto se conoce como compaction.
Se utilizan Bloom filters para verificar si una entrada podría estar en uno de los archivos.