Los deadlocks en los sistemas distribuidos son más difíciles de evitar, prevenir, o incluso detectar. También es más difícil resolverlos una vez fueron encontrados, ya que la información relevante se encuentra dispersa en diferentes geográficamente. Existen distintos algoritmos para lidiar con deadlocks.
Algoritmos de Detección
Prevenirlos es difícil, por lo que se desarrollaron métodos para poder detectar los métodos una vez ocurrieron.
Algoritmo Centralizado
Un primer enfoque trata de imitar un algoritmo no distribuido para la detección de deadlocks.
El proceso coordinador mantiene el grafo de uso de recursos, los procesos envían mensaje al coordinador cuando obtienen/liberan un recurso, y el coordinador actualiza el grafo.
En cuento el coordinador detecta un ciclo en el grafo, puede indicarle a uno de los procesos que debe abortar.
Un posible problema puede llegar ser que los mensajes lleguen desordenados, y generar falsos deadlocks. Una posible solución es utiliza timestamps globales para ordenar los mensajes.
Algoritmo Distribuido
Cuando un proceso debe esperar por un recurso, envía un probe message al proceso que tiene el recurso. El mensaje contiene:
- Identificador del proceso que se bloquea.
- Identificador el proceso que envía el mensaje.
- Identificador el proceso destinatario.
Al recibir el mensaje, el proceso actualiza el identificador del proceso que envía y el identificador del destinatario, y lo envía a los procesos que tienen el recurso que necesita.
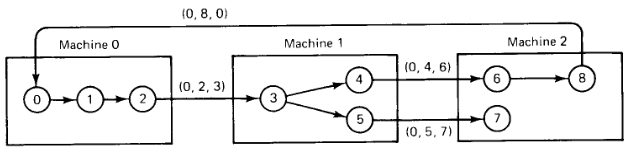
En el diagrama solo ve muestran los mensajes enviados entre computadoras distintas. Una vez el mensaje vuelve al proceso 0, se detecta un ciclo, por lo que el proceso 0 abortará.
Un algoritmo alternativo consiste en que cada proceso agregue su identificador al mensaje. Una vez se alcanza un deadlock, se puede ver cuál es el proceso de mayor identificador y eliminarlo (o enviarle un mensaje para que se suicide).
Algoritmos de Prevención
Estos algoritmos consisten en diseñar un sistema bajo el cual los deadlocks son estructuralmente imposibles.
Algoritmo Wait-Die
Se asigna un timestamp único y global a cada transacción al inicial (algoritmo de Lamport).
Cuando un proceso está por bloquearse en un recurso (que tiene otro proceso), se comparan los timestamps.
- Si el timestamp propio es menor (el proceso es más viejo), espera.
- Si no, el proceso aborta la transacción.
De esta forma, en una cadena de bloqueos, los timestamps solo incrementan, por lo que un ciclo es estructuralmente imposible.
Si bien se puede hacer que el proceso más viejo sea el que aborte, es más intuitivo el sentido contrario, ya que un proceso más viejo tiende a tener más recursos y más tiempo invertido, por lo que no es bueno abortarlo.
Algoritmo Wound-Wait
Se asigna un timestamp único y global a cada transacción al inicial (algoritmo de Lamport)
Cuando un proceso está por bloquearse en un recurso (que tiene otro proceso), se comparan los timestamps.
- Si el timestamp propio es menor (el proceso es más viejo), se aborta la transacción del proceso que tiene el recurso, para que el más viejo pueda tomarlo.
- Si no, el proceso espera.
Nuevamente, se prioriza a los procesos más viejos, ya que tienen más tiempo invertido.