Aún quedan por entender las políticas de alto nivel que emplea el scheduler del sistema operativo. Para empezar, realizaremos algunas suposiciones irrealistas respecto al workload de los procesos.
Métrica: Turnaround
Empezaremos con una métrica simple llamada turnaround time. Esta representa el tiempo que tarda un proceso en ejecutarse desde que llega al sistema.
Esta métrica es una métrica de rendimiento, lo cual va a ser nuestra principal preocupación en este capítulo. Vamos a analizar como se comporta esta métrica con distintas políticas.
FIFO: First in, First out
Es la técnica más simple, cuando dos procesos llegan exactamente al mismo tiempo, se selecciona uno al azar. El problema de esta política surge cuando nuestros procesos tienen duraciones distintas. Si el primer proceso es largo, entonces el sistema tendrá un rendimiento bajo.
Este efecto es conocido como convoy effect, procesos cortos quedan atascados detrás de un proceso largo.
SJF: Shortest Job First
Si suponemos que conocemos el tiempo de ejecución de un proceso de antemano, entonces podemos ejecutar primero el más corto para maximizar el rendimiento promedio de nuestro sistema. Si suponemos que todos los procesos llegan a la vez, esta técnica es la óptima. Lamentablemente, ninguno de los dos supuestos es real.
STCF: Shortest Time-to-Completion
Esta técnica busca atacar el problema de que los procesos lleguen a destiempo. En todo momento, se está corriendo el proceso que menos tiempo tardaría en completarse. En cuanto llega un nuevo proceso, podemos cambiarnos a ese proceso si este tardaría menos en ejecutarse. Bajo algunos supuestos irrealistas y utilizando la métrica turnaround, entonces esta técnica es la idea.
Métrica: Response Time
La introducción de las máquinas timeshare cambio el paradigma, ya no es solo fundamental mejorar el rendimiento, sino lograr que los procesos se ejecuten en lo antes posible, teniendo en cuenta el tiempo de reacción humano. Si esto no se cumple, podría parecer que el sistema se tildó.
Debido a esto, surge una nueva métrica llamada response time. Esta representa que tarda un proceso en empezar a ejecutarse, desde que llega al sistema.
Round Robin
Para tratar de favorecer esta técnica, surge el round robin. Todos los procesos corren durante un time slice, un periodo determinado de tiempo. Luego, se ejecuta el próximo proceso en la cola. Esto se repite hasta que no haya más procesos por ejecutar. Muchas veces, esta técnica es conocida como time-slicing. Este algoritmo es bueno cuando los procesos tardan lo mismo en ejecutarse.
El largo del time-slice es crítico, cuanto menor eso, mejor resulta la métrica de response-time, aunque hacerlos muy cortos es problemático, ya que se destinan muchos recursos al context-switch. Este costo no solo viene de cargar y guardar los registros, sino también de otros componentes, como la memoria caché.
Lamentablemente, este algoritmo es muy malo cuando analizamos la métrica turnaround. Todas las políticas fair o justas que distribuyen los procesos en una escala pequeña de tiempo, tienden a tener un peor rendimiento general en esta métrica.
Entrada / Salida
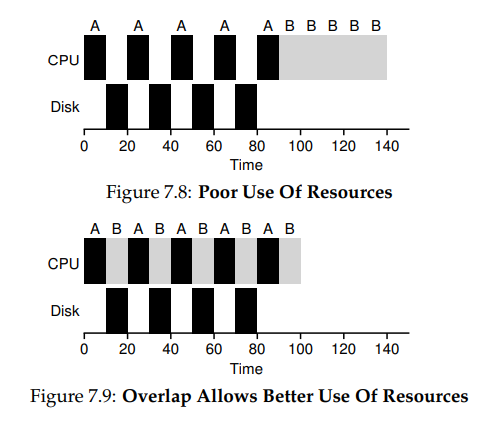
Cuando incorporamos este elemento, debemos tener en cuenta algunas cosas. Cuando un proceso inicia un pedido de I/O, entonces este se bloquea esperando a que el pedido finaliza. En estos casos, el procesador probablemente deba cambiar de proceso y ejecutar otro mientras tanto.
Si esto no se hace, el procesamiento se puede tornar lento cuando algunos procesos ejecutan entrada salida.
Última Suposición
Finalmente, debemos enfrentar nuestro último supuesto. El procesador suele tener muy poca información respecto a la longitud de un proceso antes de que este se ejecute. Debido a esto, no podemos tenerlo en cuenta para nuestras políticas.