Ahora, abordaremos el segundo problema principal de la paginación, su gran consumo de memoria.
Con una tabla de páginas lineal, asumiendo que trabajamos con un espacio de direcciones de 32-bits y el tamaño de cada chunk es de 4 KB, tendremos entonces aproximadamente un millón de páginas virtuales, si las multiplicamos con el tamaño de una entrada en la tabla de páginas, estaremos ocupando 4 MB por proceso.
Solución Simple: Páginas más grandes
Su aumentamos el tamaño de las páginas a, digamos 16 KB, entonces estaremos utilizando 1 MB por proceso, un tamaño mucho menor. El problema con esta solución es que la utilización de páginas más grandes lleva a desperdiciar memoria, con el problema de la fragmentación interna.
Enfoque Híbrido: Páginas y Segmentos
Muchas veces, nuestra tabla de páginas estará en su mayoría vacía, gastando mucha memoria en entradas inválidas.
Una forma de solucionar esto es utilizar el enfoque híbrido. De esta forma, tendremos una tabla de páginas para cada segmento lógico: stack, code, heap. De esta forma, utilizamos el registro base para apuntar a la dirección de física donde se almacena dicha página de tablas. El registro bound se utiliza para indicar el final de la tabla de páginas, es decir, la cantidad de páginas válidas.
De esta forma, no reservaremos memoria para nuestras tablas completas, sino únicamente para lo que necesitamos. Esto reduce significativamente la cantidad de memoria.
Este enfoque tiene aún sus desventajas, surge la fragmentación externa. Las páginas de tablas tienen un tamaño arbitrario, por lo que encontrar espacio libre para ellas puede ser un problema.
Tablas de Multi-Paginación
Este enfoque es tan efectivo qué inclusa se utiliza en los sistemas modernos. Consiste en no tener un únicamente tabla de páginas, sino utilizar una estructura de árboles para las tablas.
La idea principal es separar la tabla de páginas es unidades del tamaño de una página. Si la página entera es inválida, entonces no se reserva memoria para ella. Esta solución introduce una nueva estructura, page directory. Esta será una tabla de punteros a tablas de páginas, más pequeñas. Indicando si una tabla es válida o no.
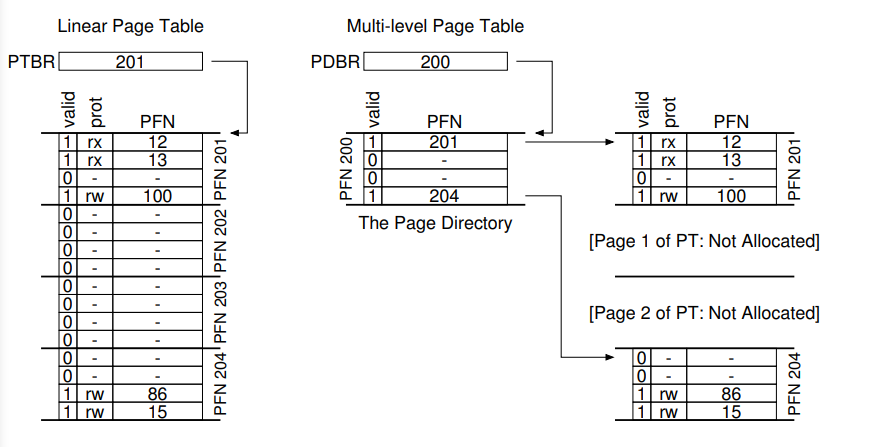
En esencia, la multi-paginación utiliza tablas de multi-nivel. Los directorios tienen una cantidad de PDE o page directory entries. Mínimamente, estos contienen un bit de validez y un PFN, el frame donde se encuentra la tabla de páginas.
Este enfoque tiene varias ventajas obvias. En primer lugar, solo se reserva memoria para las páginas que se utilizan por proceso, lo que ahorra mucha memoria.
Por otro lado, las páginas de tablas pueden entrar cuidadosamente en un frame, por lo que no tendremos fragmentación externa.
Además, al no tener la memoria contigua, es más fácil encontrar espacio libre para las tablas. Esto es así, ya que agregamos un nivel de indirección.
En contraste, esta solución es un poco más costosa, puesto que tendremos dos accesos a memoria. Uno para la page directory, y otro para la page table.. Esta solución también es un poco más compleja que las tablas lineales, pero a veces es necesario utilizar soluciones complejas, teniendo en cuenta el trade-off que ofrecen.
Esta solución es un claro ejemplo de time-space trade-off, sacrificamos un poco de tiempo para obtener mucho espacio. Aunque en algunas situaciones, debido a las TLB, el rendimiento es prácticamente idéntico.
Tablas Profundas
A veces, utilizar únicamente dos niveles de paginación no es suficiente. Cuando tenemos un espacio de direcciones grande, con pequeños chunks, necesitaremos incluso más indirección para no consumir demasiada memoria, y poder lograr que todas nuestras tablas se ajusten al tamaño de un chunk.
Cuando nos encontramos con que nuestro page directory es muy grande, podemos considerar partirlo nuevamente en chunks para añadir un nuevo nivel de indirección.
Proceso de Traducción
Para realizar la traducción, primero debemos acceder a la entrada de la page directory correspondiente. Luego, a partir de la page table, accedemos PTE que contiene nuestra traducción. Por suerte, debido al caché, solo debemos realizar esta búsqueda cuando nos encontramos con un TLB miss.
Tablas Invertidas
Esta solución, un poco más extrema, consiste en tener una únicamente tabla para todas las tablas físicas del sistema, almacenando información sobre qué procesos tienen acceso a esa tabla, y cuál es el mapeo correspondiente. Encontrar la traducción ahora consiste en buscar en esta tabla.(utilizamos una estructura tipo hash para ahorrarnos cómputo)
Swapping Tables to Disk
Incluso con todos las soluciones discutidas anteriormente, es posible que las tablas sean muy grandes para entrar en memoria. En estos casos pondremos estas tablas en la kernel virtual memory, permitiendo al sistema que las intercambie al disco cuando nos quedamos sin memoria.