El enfoque tomado por TCP entonces es que cada remitente limite la tasa a la cual envía tráfico a través de su conexión en función de la congestión recibida.
Este mecanismo mantiene una variable adicional llamada congestion window denotada cwnd. La cantidad de datos sin confirmar no debe ser mayor al mínimo entre la congestion window y receiver window.
Definiremos un loss event en un TCP sender como la ocurrencia de un timeout o la recepción de tres duplicate ACK. Cuando hay excesiva congestión, entonces se perderán paquetes a lo largo de la ruta y ocasionarán loss events. Debido a que TCP utiliza ACK (o un timer) para configurar su ventana de congestión, se dice de ser self-clocking.
Para decidir como exactamente se modificara la ventana de congestión, se seguirán los siguientes principios:
- Un segmento perdido implica congestión, y el remitente deberá reducir su tasa de transmisión cuando esto ocurre
- La confirmación de un paquete indica que la red está entregando los segmentos, y el remitente deberá aumentar su tasa de transmisión.
La estrategia de TCP entonces será la de bandwith probing. La tasa de transmisión se aumentará lentamente en respuesta a los ACK recibidos y disminuirá al encontrarse con una perdida. El objetivo es alcanzar una velocidad estable que no cause perdida de paquetes.
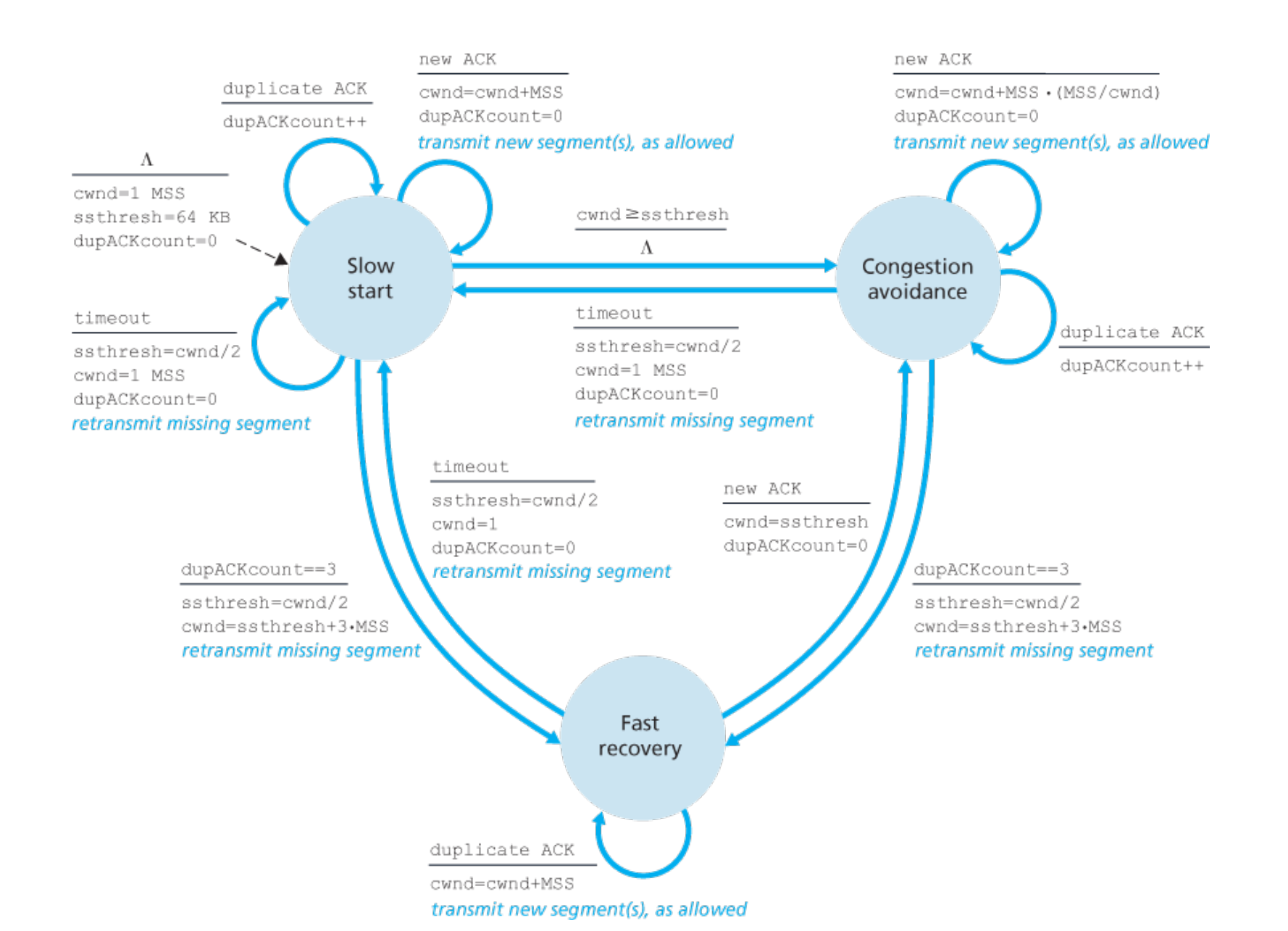
Ahora podremos definir el algoritmo de congestión de control de TCP, el cual tiene tres componentes principales: slow start, congestion avoidance, fast recovery.
Slow Start
Cuando se inicia una conexión TCP, se inicializa el valor de cwdn con un valor pequeño, de usualmente 1 MSS. En el estado de slow start el cwdn es aumentado en uno por cada ACK recibido, esencialmente duplicando la tasa de envío cada RTT.
Si ocurre un timer interrupt, se asigna sstresh = cwnd/2 y se vuelve a establecer cwdn al valor inicial, reiniciando el proceso. Cuando cwnd alcanza o sobrepasa sstresh, se avanza al estado de congestion avoidance mode. Si se reciben tres duplicados, entonces TCP ingresa al estado de fast recovery.
Congestion Avoidance
En lugar de duplicar el valor de cwdn cada RTT, TCP adopta un enfoque más conservativo. Se aumenta 1 MSS por cada RTT.
Cuando ocurre un timer interrupt, se realiza lo mismo que en el estado de slow start. Ante la llegada de tres duplicate ACK, se toma un enfoque menos drástico, en lugar de restablecer cwdn, se reduce a la mitad. Ante cualquier loss event, se ingresa al estado de fast recovery
Fast Recovery
En este estado, cwdn se incrementa en 1 MSS por cada ACK duplicado recibido por un segmento perdido que causo el fast-recovery state. Eventualmente, cuando se recibe un ACK por el segmento perdido, TCP entra en congestion-avoidance luego de reducir cwdn a sstresh Ante un timeout event, se restablece cwdn y sstresh de la misma forma que antes y se pasa al estado de slow start.
Una versión inicial de TCP, conocida como TCP Tahoe no implementaba fast-recovery. Fue introducido posteriormente por TCP Reno
TCP Congestion Control: Retrospective
En esencia, el mecanismo consiste en incrementos lineales aditivos en la ventana de congestión, y reducciones multiplicativas. Debido a esto es conocido como la forma de congestión AIMD (additive-increase-multiplicative-decrease).
El algoritmo TCP Vegas intenta evitar congestión manteniendo un buen throughput. Para hacerlo, detecta congestión en los routers antes de que ocurre la perdida de paquetes y reduce la tasa linealmente cuando se detecta una perdida de paquetes inminente.
El algoritmo AIMD fue desarrollado tras muchos años de trabajos de ingeniería y experimentación con redes de control de congestión.
Macroscopic Description of TCP Throughput
Debido al comportamiento de sierra que presenta la tasa de producción, podemos definir el average throughput como 0.75*WRTT siendo W el valor en el cual ocurre un loss event. La tasa de transmisión oscila entre W/(2RTT) y W/RTT
TCP Over High-Bandwidth Paths
Para obtener altas velocidades de transmisión utilizando TCP, debemos conseguir una muy baja probabilidad de perdida de paquetes (utilizando la fórmula vista anteriormente). Debido a esto, hoy en día se están investigando nuevas versiones de TCP específicas para ambientes de alta velocidad.
1. Fairness
Un mecanismo de control de congestión se dice que es justo si la tasa de transmisión promedio común para todas las conexiones. Todas obtienen una porción equitativa del ancho de banda del enlace.
Si bien el algoritmo de control de congestión en la teoría es justo. En la práctica, los hosts con menos RTT tienden a obtener mejor throughput que aquellos con mayor RTT.
Fairness and UDP
Muchas aplicaciones de multimedia prefieren utilizar UDP para que su tasa de transmisión no se vea entorpecida por el mecanismo de control de congestión. Desde la perspectiva de TCP, estas aplicaciones multimedia no están siendo justas con el resto de usuarios.
Fairness and Parallel TCP Connections
Incluso si podemos forzar a que el tráfico de UDP se comporte de forma justa, el problema no está totalmente resuelto. Nada impide a una aplicación basada en TCP de utilizar múltiples conexiones paralelas, efectivamente obteniendo una mayor porción del bandwidth en un medio congestionado.
2. Explicit Congestion Notification (ECN): Network-assisted Congestion Control
Recientemente, fueron surgieron extensiones de IP y TCP para permitir a la red señalar congestión en la red de forma explícita, a través de dos bits en el campo Type of Service del IP datagram. Este tipo de congestión de control se conoce como explicit congestion notification.
Uno de los bits es utilizado para indicar que el router está experimentando congestión, mientras que el otro se utiliza para indicarle a los routers que los senders y receivers son ECN-capable.
Si bien el RFC no provee una definición para cuando el router está congestionado, se recomienda que únicamente lo indique ante congestión persistente.
Existen otros protocolos de transporte además de TCP que hacen uso de este mecanismo. DCCP (Datagram Congestion Control Protocol) provee un servicio similar a UDP que utiliza control de congestión. DCTCP (Data Center TCP) es una versión de TCP diseñada específicamente para redes de data center, que hace uso de ECN.